
In the Fall of 2012, I led the development and publication of a discussion paper for the Kantara Initiative Identity Assurance Working Group. The paper explored the concept of a general model for the Credential Provider – Identity Provider – Online Service Provider architecture.
I identified several abstract Roles, Actors, Functions and Relationships that appeared in many of the identity frameworks and architectures, then proceeded to create a general model showing how everything was related.
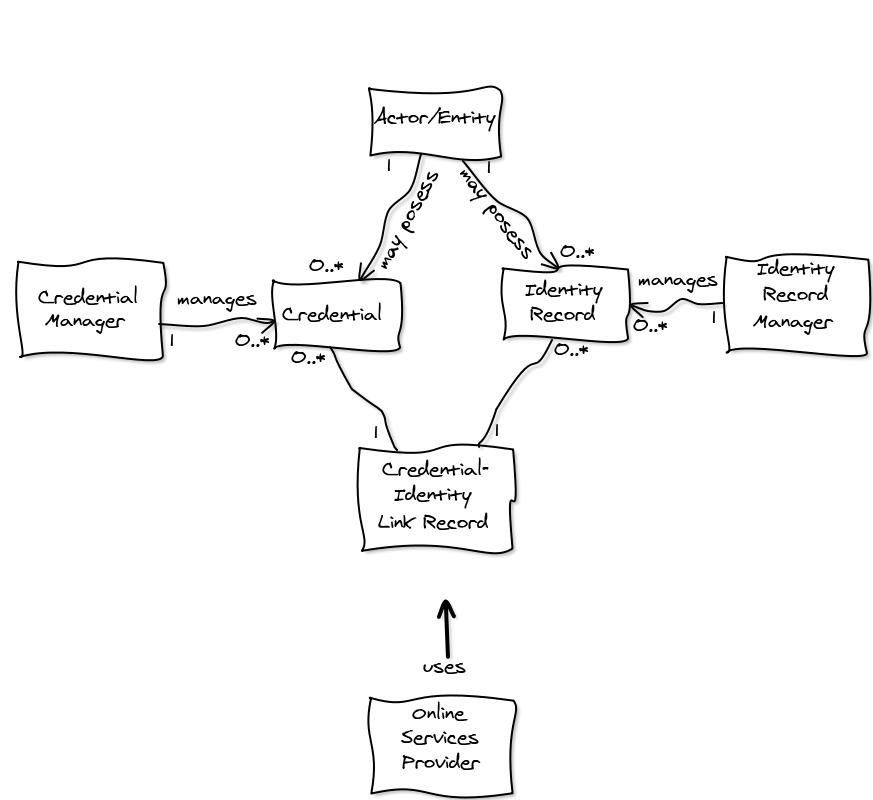
The paper received some interest when presented to a Kantara Initiative workshop in late 2012. It has also sparked renewed interest and expansion from Anil John, as he explores the concept and implications of Credential Manager and Identity Manager separation, in particular as it relates to US FICAM Trust Frameworks and NIST 800-63-1/2.
In several posts, Anil has refined the original general model in interesting ways, and now uses it to test ideas on anonymity, privacy, separation of roles and other topics.
The refined model looks like:
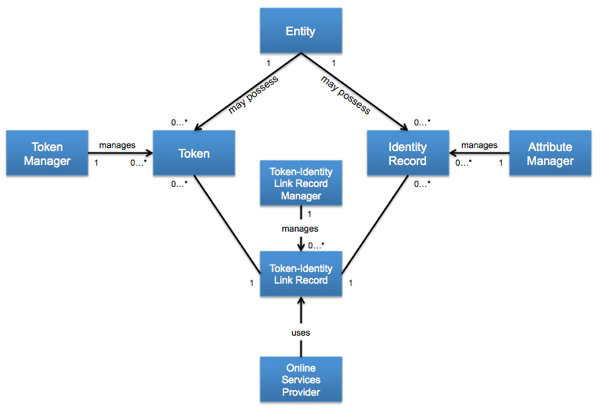
The names of the “Manager” roles have been changed to align to NIST 800-63 language (I was using terms typically used in Canada for these roles), and an explicit manager for the Token-Identity Link Record has been created (this becomes the ‘Credential Manager’ in future revisions.
These models have proven to be very effective in communicating to our peers about this topic. But there is unfinished business.
One of the original goals of the Kantara paper was to map out the Functions that could be assigned to Roles, and to dig deeper into the relationships between the Roles. The time has come to start this work.
It seems that several big topics are being debated in the Trusted Identity field these days:
- Attribute providers are the real ‘information emitters’ – there’s no such thing as ‘Identity Providers’ – so how should Attribute providers be evaluated versus Level of Assurance schemes?
- How can a Trust Framework Provider describe assessment criteria, then have an assessment performed reliably, when Attribute Providers and “Identity Oracles” proliferate?
- What are the implications of aggregating attributes from several providers as it relates to assurance and confidence in accuracy and validity of the information?
- How could subsets of the Roles and Functions in the model be aggregated dynamically (or even statically) to satisfy the identity assurance risk requirements of an RP?
A small team has been assembled under the auspices of the Kantara IAWG, and I hope to lead us through the conversation and debate as we extend the general model and explore it in light of temporal events, LOA mappings, Trust Framework comparability mappings, and core Trusted Identity Functions. Once we have figured out a richer general model, the meatier discussion can begin: which elements, agglomerations, and segments of the model can be assessed and issued a Trusted Identity Trustmark in a meaningful way – one that is valued by service providers and consumers.
The Trustmark question cannot be addressed until the general model is elaborated – and the outcome will be a greater community understanding of the nature of attribute managers, LOA and how attributes could be trusted in the to-be-invented identity attributes universe.
More to come…

One thought on “Evolution of a Trusted Identity Model”